- 02 8月, 2019 18 次提交
-
-
由 Hong Xu 提交于
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/23617 Doesn't seem to cause any performance regression. Performance difference in the benchmarks is negligible. Benchmark script: ```python import timeit for n, t in [(10, 100000), (1000, 10000)]: print('a.neg() (a.numel() == {}) for {} times'.format(n, t)) for device in ('cpu', 'cuda'): for dtype in ('torch.int8', 'torch.uint8', 'torch.int16', 'torch.int32', 'torch.int64', 'torch.float', 'torch.double') + (('torch.half',) if device == 'cuda' else ()): print(f'device: {device}, dtype: {dtype}, {t} times', end='\t\t') print(timeit.timeit(f'a.neg()\nif "{device}" == "cuda": torch.cuda.synchronize()', setup=f'import torch; a = torch.ones({n}, device="{device}", dtype={dtype})', number=t)) ``` Before: ``` a.neg() (a.numel() == 10) for 100000 times device: cpu, dtype: torch.int8, 100000 times 2.5537249100016197 device: cpu, dtype: torch.uint8, 100000 times 2.512518662999355 device: cpu, dtype: torch.int16, 100000 times 2.548207502000878 device: cpu, dtype: torch.int32, 100000 times 2.5974994509997487 device: cpu, dtype: torch.int64, 100000 times 2.6533011499996064 device: cpu, dtype: torch.float, 100000 times 2.6474813019995054 device: cpu, dtype: torch.double, 100000 times 2.6949866009999823 device: cuda, dtype: torch.int8, 100000 times 5.820120684998983 device: cuda, dtype: torch.uint8, 100000 times 5.732108927997615 device: cuda, dtype: torch.int16, 100000 times 5.791249125999457 device: cuda, dtype: torch.int32, 100000 times 5.816761754998879 device: cuda, dtype: torch.int64, 100000 times 5.935873205999087 device: cuda, dtype: torch.float, 100000 times 6.276509613999224 device: cuda, dtype: torch.double, 100000 times 6.122782447000645 device: cuda, dtype: torch.half, 100000 times 6.161522764999972 a.neg() (a.numel() == 1000) for 10000 times device: cpu, dtype: torch.int8, 10000 times 0.3766637519984215 device: cpu, dtype: torch.uint8, 10000 times 0.37288786600038293 device: cpu, dtype: torch.int16, 10000 times 0.3485262310023245 device: cpu, dtype: torch.int32, 10000 times 0.41810554200128536 device: cpu, dtype: torch.int64, 10000 times 0.5609612200023548 device: cpu, dtype: torch.float, 10000 times 0.39054008099992643 device: cpu, dtype: torch.double, 10000 times 0.4946578170020075 device: cuda, dtype: torch.int8, 10000 times 0.5843639539998549 device: cuda, dtype: torch.uint8, 10000 times 0.5780841570012853 device: cuda, dtype: torch.int16, 10000 times 0.5819949180004187 device: cuda, dtype: torch.int32, 10000 times 0.5827294059999986 device: cuda, dtype: torch.int64, 10000 times 0.5861426519986708 device: cuda, dtype: torch.float, 10000 times 0.5929420489992481 device: cuda, dtype: torch.double, 10000 times 0.594638443999429 device: cuda, dtype: torch.half, 10000 times 0.5903799709994928 ``` After: ``` a.neg() (a.numel() == 10) for 100000 times device: cpu, dtype: torch.int8, 100000 times 2.4983287129980454 device: cpu, dtype: torch.uint8, 100000 times 2.479393904999597 device: cpu, dtype: torch.int16, 100000 times 2.5382055320005747 device: cpu, dtype: torch.int32, 100000 times 2.5587980189993687 device: cpu, dtype: torch.int64, 100000 times 2.637738788002025 device: cpu, dtype: torch.float, 100000 times 2.602799075997609 device: cpu, dtype: torch.double, 100000 times 2.6648931070012623 device: cuda, dtype: torch.int8, 100000 times 5.793338211999071 device: cuda, dtype: torch.uint8, 100000 times 5.782462584000314 device: cuda, dtype: torch.int16, 100000 times 5.824340334998851 device: cuda, dtype: torch.int32, 100000 times 5.851659068001027 device: cuda, dtype: torch.int64, 100000 times 5.8898071570001775 device: cuda, dtype: torch.float, 100000 times 5.913144636000652 device: cuda, dtype: torch.double, 100000 times 5.963339805999567 device: cuda, dtype: torch.half, 100000 times 5.87889370099947 a.neg() (a.numel() == 1000) for 10000 times device: cpu, dtype: torch.int8, 10000 times 0.37244726499920944 device: cpu, dtype: torch.uint8, 10000 times 0.36641623199830065 device: cpu, dtype: torch.int16, 10000 times 0.3449854829996184 device: cpu, dtype: torch.int32, 10000 times 0.4127863069988962 device: cpu, dtype: torch.int64, 10000 times 0.5551902160004829 device: cpu, dtype: torch.float, 10000 times 0.38593814199703047 device: cpu, dtype: torch.double, 10000 times 0.48877579500185675 device: cuda, dtype: torch.int8, 10000 times 0.5862828740027908 device: cuda, dtype: torch.uint8, 10000 times 0.5836667540024791 device: cuda, dtype: torch.int16, 10000 times 0.5918155769977602 device: cuda, dtype: torch.int32, 10000 times 0.5961457039993547 device: cuda, dtype: torch.int64, 10000 times 0.5963898690024507 device: cuda, dtype: torch.float, 10000 times 0.5985483309996198 device: cuda, dtype: torch.double, 10000 times 0.6027148480025062 device: cuda, dtype: torch.half, 10000 times 0.5961164370019105 ``` Test Plan: Imported from OSS Differential Revision: D16617574 Pulled By: ezyang fbshipit-source-id: c90aa410f6385ce94fe6b84ebeceffa5effd0267
-
由 Dmytro Dzhulgakov 提交于
Summary: Adds new people and reorders sections to make more sense Pull Request resolved: https://github.com/pytorch/pytorch/pull/23693 Differential Revision: D16618230 Pulled By: dzhulgakov fbshipit-source-id: 74191b50c6603309a9e6d14960b7c666eec6abdd
-
由 Owen Anderson 提交于
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/23659 Differential Revision: D16603775 fbshipit-source-id: f2912048bdee36b3bcaa779e801c61bfbb5f30e5
-
由 Nikolay Korovaiko 提交于
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/23060 Differential Revision: D16460391 Pulled By: Krovatkin fbshipit-source-id: b50ee87d22ad18b8cbfff719b199ea876ef172f1
-
由 James Reed 提交于
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/23690 Test Plan: Imported from OSS Reviewed By: suo Differential Revision: D16610734 Pulled By: jamesr66a fbshipit-source-id: e190174f11d1810e6f87e2df256543028e9154ef
-
由 Hao Lu 提交于
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/23705 Reviewed By: yinghai Differential Revision: D16354204 fbshipit-source-id: 158b0ee556606c117e52bee875d3dc89cc944b5a
-
由 Wanchao Liang 提交于
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/23266 Test Plan: Imported from OSS Differential Revision: D16466586 Pulled By: wanchaol fbshipit-source-id: 0f5b8013167bb7b246bd7e28d87a4a9e9c3b34d5
-
由 Mikhail Zolotukhin 提交于
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/23692 Before tests took ~40s to finish, with this change it's ~2s. Test Plan: Imported from OSS Differential Revision: D16611479 Pulled By: ZolotukhinM fbshipit-source-id: 391235483029d2ab860fcc4597ce84f4964025f1
-
由 svcscm 提交于
Reviewed By: zpao fbshipit-source-id: ff6387055e7fa2cde88bd870081a05c3adbf56ef
-
由 Tongzhou Wang 提交于
Summary: fixes https://github.com/pytorch/pytorch/issues/23642 Pull Request resolved: https://github.com/pytorch/pytorch/pull/23646 Differential Revision: D16600874 Pulled By: soumith fbshipit-source-id: 50f0828d774a558d6f21e9dd21135906bd5be128
-
由 Vitaly Fedyunin 提交于
Summary: Move CPU implementation of the `addcmul` operator to Aten ( https://github.com/pytorch/pytorch/issues/22797 ) ### before ```python In [11]: timeit x.addcmul(a, b) 1.31 ms ± 18.3 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each) ``` ### after ```python In [9]: timeit x.addcmul(a, b) 588 µs ± 22.8 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each) ``` Adding custom code for the case when `value == 1`, doesn't provide significant performance gain. Pull Request resolved: https://github.com/pytorch/pytorch/pull/22874 Differential Revision: D16359348 Pulled By: VitalyFedyunin fbshipit-source-id: 941ead835672fca78a1fcc762da052e64308b111
-
由 Soumith Chintala 提交于
Summary: add setup metadata to help PyPI flesh out content on pypi package page. Apparently this might help flesh out the "Used By" feature according to driazati Pull Request resolved: https://github.com/pytorch/pytorch/pull/22085 Differential Revision: D16604703 Pulled By: soumith fbshipit-source-id: ddb4f7ba7c24fdf718260aed28cc7bc9afb46de9
-
由 Bram Wasti 提交于
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/23210 Test Plan: Imported from OSS Differential Revision: D16444529 Pulled By: bwasti fbshipit-source-id: 83af54d423989a2a726158b521093660584ee9c2
-
由 Tongzhou Wang 提交于
Summary: cc gchanan Pull Request resolved: https://github.com/pytorch/pytorch/pull/23671 Differential Revision: D16604387 Pulled By: soumith fbshipit-source-id: 0ebc120bcaa0f6fa09158b1d0459a72ab11a53d6
-
由 Rui Zhu 提交于
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/23663 Reviewed By: yinghai Differential Revision: D16592163 fbshipit-source-id: de1482305abef45f7ef0e3e57b0c93cd2acac450
-
由 Farhad Ramezanghorbani 提交于
Summary: I have noticed a small discrepancy between theory and the implementation of AdamW and in general Adam. The epsilon in the denominator of the following Adam update should not be scaled by the bias correction [(Algorithm 2, L9-12)](https://arxiv.org/pdf/1711.05101.pdf). Only the running average of the gradient (_m_) and squared gradients (_v_) should be scaled by their corresponding bias corrections. 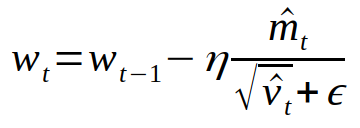 In the current implementation, the epsilon is scaled by the square root of `bias_correction2`. I have plotted this ratio as a function of step given `beta2 = 0.999` and `eps = 1e-8`. In the early steps of optimization, this ratio slightly deviates from theory (denoted by the horizontal red line). 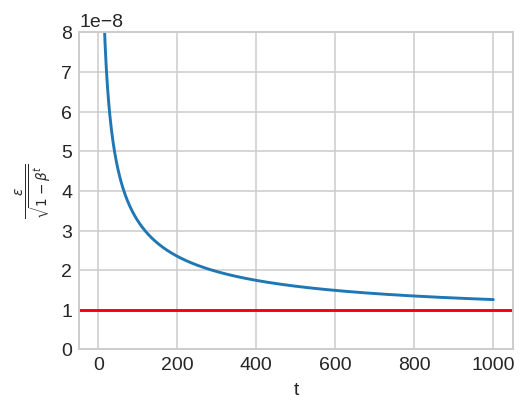 Pull Request resolved: https://github.com/pytorch/pytorch/pull/22628 Differential Revision: D16589914 Pulled By: vincentqb fbshipit-source-id: 8791eb338236faea9457c0845ccfdba700e5f1e7
-
由 Jerry Zhang 提交于
Summary: Added _intrinsic.qat.ConvBn2d/_intrinsic.qat.ConvBnReLU2d. Pull Request resolved: https://github.com/pytorch/pytorch/pull/23357 ghstack-source-id: 87519573 Differential Revision: D16295500 fbshipit-source-id: 81e6d1d10d05bf6e343721fc5701d3d6bd7e07e6
-
由 Elias Ellison 提交于
Summary: As far as I could tell forward hooks work out of the box, so allow them in the tracing. We don't have any way of supporting backward hooks though. Fixes https://github.com/pytorch/pytorch/issues/20862 and fixes https://github.com/pytorch/pytorch/issues/17571 Pull Request resolved: https://github.com/pytorch/pytorch/pull/23613 Differential Revision: D16601437 Pulled By: eellison fbshipit-source-id: ecf5dc6201ca08b3b9afdb9fcdb0fda8741133a9
-
- 01 8月, 2019 22 次提交
-
-
由 Edward Yang 提交于
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/23654 Default configuration at time of writing is CUDA 10 (but with 10.1 coming soon) Signed-off-by:
Edward Z. Yang <ezyang@fb.com> Test Plan: Imported from OSS Differential Revision: D16601097 Pulled By: ezyang fbshipit-source-id: c8368355ce1521c01b0ab2a14b1cd0287f554e66
-
由 Edward Yang 提交于
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/23611Signed-off-by:
-
由 Iurii Zdebskyi 提交于
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/21113 ghimport-source-id: 9c4ba63457a72bfc41894387e0b01be3fd9a9baf Test Plan: Imported from OSS Differential Revision: D15552204 Pulled By: izdeby fbshipit-source-id: a608213668649d058e22b510d7755cb99e7d0037
-
由 Hong Xu 提交于
Summary: Currently once user has set `USE_NATIVE_ARCH` to OFF, they will never be able to turn it on for MKLDNN again by simply changing `USE_NATIVE_ARCH`. This commit fixes this issue. Following up 09ba4df0 Pull Request resolved: https://github.com/pytorch/pytorch/pull/23608 Differential Revision: D16599600 Pulled By: ezyang fbshipit-source-id: 88bbec1b1504b5deba63e56f78632937d003a1f6
-
由 Sebastian Messmer 提交于
Summary: We need this to be able to register them with the c10 dispatcher. The overload names are based on one-letter-per-argument-type. Script used to change native_functions.yaml and derivatives.yaml: P75630718 Pull Request resolved: https://github.com/pytorch/pytorch/pull/23532 ghstack-source-id: 87539687 Differential Revision: D16553437 fbshipit-source-id: a1d0f10c42d284eba07e2a40641f71baa4f82ecf
-
由 mal 提交于
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/23618 For example: `save_for_backward({Variable(), x, Variable()})` should be allowed, so that this is consistent with the python API behaviour. Test Plan: Added a test similar to the python test `test_save_none_for_backward` from test_autograd.py. Differential Revision: D16589402 fbshipit-source-id: 847544ad8fc10772954d8629ad5a62bfdc1a66c1
-
由 Ailing Zhang 提交于
Summary: Fixes https://github.com/pytorch/pytorch/issues/23607 Pull Request resolved: https://github.com/pytorch/pytorch/pull/23629 Differential Revision: D16594223 Pulled By: soumith fbshipit-source-id: db0275415111f08fc13ab6be00b76737a20f92df
-
由 Michael Suo 提交于
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/23630 This is temporary, won't be needed with the new serialization format. But for now, since the main module gets its name from the archive name, we need this for safety, other wise something like `torch.jit.save("torch.pt") will break things. Test Plan: Imported from OSS Reviewed By: jamesr66a Differential Revision: D16592404 Pulled By: suo fbshipit-source-id: b538dc3438a80ea7bca14d84591ecd63f4b1289f
-
由 Bram Wasti 提交于
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/23557 As title states this enables any tensors defined by the user to be outputs, including activations Reviewed By: yinghai Differential Revision: D16362993 fbshipit-source-id: b7dc8412c88c46fcf67a3b3953dc4e4c2db8c4aa
-
由 Tongzhou Wang 提交于
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/23615 Differential Revision: D16590899 Pulled By: zou3519 fbshipit-source-id: 4f07eda93fd618605c3bb6dfe4c11b2d1d2dec0d
-
由 Michael Suo 提交于
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/23627 Test Plan: Imported from OSS Differential Revision: D16590415 Pulled By: suo fbshipit-source-id: 9f4fabd77b80f08f96f4bc969b43aa8ff3d4ac96
-
由 Nikolay Korovaiko 提交于
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/23383 Differential Revision: D16573661 Pulled By: Krovatkin fbshipit-source-id: c199656805b474b3c1b3ba09b4e236aec84617f4
-
由 Thomas Viehmann 提交于
Summary: Fixes: https://github.com/pytorch/pytorch/issues/18215 at last! Also sprinkle tests... Pull Request resolved: https://github.com/pytorch/pytorch/pull/23298 Differential Revision: D16582145 Pulled By: soumith fbshipit-source-id: bc8b1a629de0c2606e70a2218ccd135f4a9cdc5d
-
由 Richard Zou 提交于
Summary: `is_pinned` was moved to native_functions.yaml, disabling it for named tensors. This PR re-enables its usage for named tensors. I wrote a named inference rule for torch.clone(), but something happened to it. Disable it for now so we can get the namedtensor ci to be green. Pull Request resolved: https://github.com/pytorch/pytorch/pull/23597 Test Plan: - run tests [namedtensor ci] Differential Revision: D16581771 Pulled By: zou3519 fbshipit-source-id: 498018cdc55e269bec80634b8c0a63ba5c72914b
-
由 mal 提交于
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/23572 ### **(The stack from #23020 was moved into this PR)** Adding API for custom autograd operations, with user defined forward and backward, [like in python](https://pytorch.org/docs/stable/notes/extending.html#extending-torch-autograd). The custom operation should be a subclass of Function, with static forward and backward functions. `forward()` can accept any arguments similar to the Python API and `backward()` should accept a variable list as an argument. Both `forward()` and `backward() `accept a AutogradContext* which can be used to share data between them. Variables can be saved in the context using `save_for_backward()` and other data can be saved in the map `save` in the form of `<std::string, at::IValue>` pairs. Variables saved in forward can be accessed with `get_saved_variables()`. Example usage: ``` class MyFunction : public Function<MyFunction> { public: static variable_list forward(AutogradContext *ctx, int n, Variable var) { // Save data for backward in context ctx->saved_data["n"] = n; return {var}; } static variable_list backward(AutogradContext *ctx, variable_list grad_output) { // Use data saved in forward auto n = ctx->saved_data["n"].toInt(); return {grad_output[0]*n}; } }; ``` Then, it can be used with: ``` Variable x; MyFunction::apply(6, x); ``` Also AutogradContext has methods to mark outputs as non differentiable and mark inputs as dirty similar to the [Python API](https://github.com/pytorch/pytorch/blob/ff23a02ac4fdf1fe76d5b24666333f1ea0a918b7/torch/autograd/function.py#L26). Test Plan: Added tests for the custom autograd function API based on test_autograd.py. Currently only the tests for the basic functionality have been added. More tests will be added later. Differential Revision: D16583428 fbshipit-source-id: 0bd42f19ce37bcd99d3080d16195ad74d40d0413
-
由 Zafar Takhirov 提交于
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/23148 Test Plan: Imported from OSS Differential Revision: D16414202 Pulled By: zafartahirov fbshipit-source-id: a999be0384a2ff5272dd2f8adcf87547ce6ee9dd
-
由 Tao Xu 提交于
Summary: ### Summary The iOS build was broken after this PR
👉 [23195](https://github.com/pytorch/pytorch/pull/23195/files) was merged, as there are two files still have dependency on ONNX. - `test.cpp` in `test/cpp/jit` - `export.cpp` in `torch/csrc/jit` This PR is to remove ONNX completely from mobile build. Pull Request resolved: https://github.com/pytorch/pytorch/pull/23546 Test Plan: - The `build_ios.sh` finished successfully. - The `libtorch.a` can be compiled and run on iOS devices Differential Revision: D16558236 Pulled By: xta0 fbshipit-source-id: b7ff1db750698cfd5a72d5cb0b9f2f378e315077 -
由 ptrblck 提交于
Summary: * Swapped `CUBLAS_OP_N` for `'n'` * added a test This PR should fix https://github.com/pytorch/pytorch/issues/23545. Thanks at AlphabetMan for reporting the initial issue reported in [the forum](https://discuss.pytorch.org/t/cuda-10-1-error-using-transposeconv2d-with-output-padding-1/51414?u=ptrblck) as well as ngimel for the guidance. Pull Request resolved: https://github.com/pytorch/pytorch/pull/23552 Differential Revision: D16580986 Pulled By: ezyang fbshipit-source-id: abc0bce1e84d9c9d96d44ae0296951725adc8424
-
由 vishwakftw 提交于
Summary: Changelog: - Add batching for det / logdet / slogdet operations - Update derivative computation to support batched inputs (and consequently batched outputs) - Update docs Pull Request resolved: https://github.com/pytorch/pytorch/pull/22909 Test Plan: - Add a `test_det_logdet_slogdet_batched` method in `test_torch.py` to test `torch.det`, `torch.logdet` and `torch.slogdet` on batched inputs. This relies on the correctness of `torch.det` on single matrices (tested by `test_det_logdet_slogdet`). A port of this test is added to `test_cuda.py` - Add autograd tests for batched inputs Differential Revision: D16580988 Pulled By: ezyang fbshipit-source-id: b76c87212fbe621f42a847e3b809b5e60cfcdb7a
-
由 Edward Yang 提交于
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/23376 This uses master version of sphinxcontrib-katex as it only recently got prerender support. Fixes #20984 Signed-off-by:
-
由 Zachary DeVito 提交于
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/23564 Test Plan: Imported from OSS Differential Revision: D16567850 Pulled By: zdevito fbshipit-source-id: 6e2056b480da3f1ea0dbb6e7240677f7e7a9937e
-
由 vishwakftw 提交于
Summary: Changelog: - Use narrow instead of narrow_copy while returning Pull Request resolved: https://github.com/pytorch/pytorch/pull/23591 Test Plan: - All tests should pass to ensure that the change is correct Fixes https://github.com/pytorch/pytorch/issues/23580 Differential Revision: D16581174 Pulled By: ezyang fbshipit-source-id: 1b6bf7d338ddd138ea4c6aa6901834dd202ec79c
-






























